Linux awk command has great advantages in text processing, which contains regular expression processing.
Usually I use the linux grep command to filter and filter text.
Today, I will introduce to you how to use the awk regular command for text filtering and processing.
Before the formal introduction, first spread a few concepts to everyone:
What Is Regex?
Usually, regular expressions or regex are the text patterns you define.
Types of Regex
Linux has two regular expression engines:
- BRE: The Basic Regular Expression engine.
- ERE: The Extended Regular Expression engine.
Compared to the BRE engine, the ERE engine comes with some programming languages that provides more patterns.
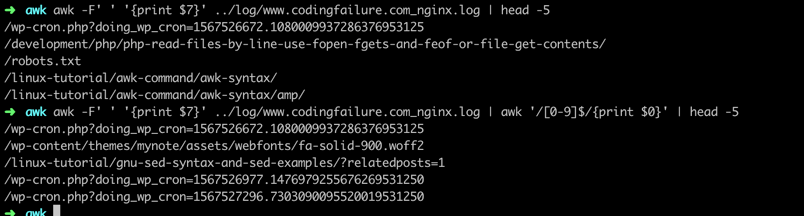
Awk using BRE regex Patterns
➜ awk '/linux-tutorial/{print $0}' ../log/www.linuxcommands.site_nginx.log | head -3
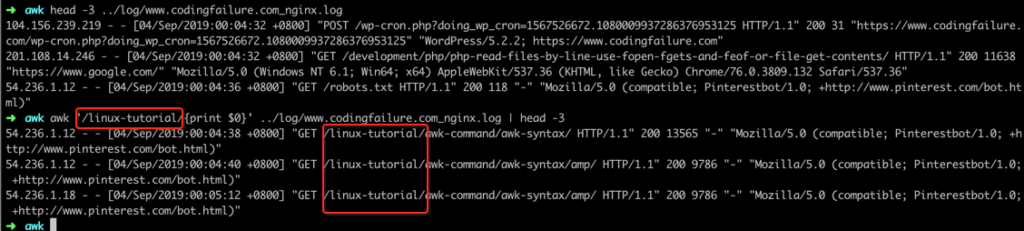
Special Characters
.*[]^${}\+?|()Sometimes you will encounter situations where special characters are handled, for example:
➜ awk -F' ' '{print $11}' ../log/www.linuxcommands.site_nginx.log | awk '/\?/{print $0}' | head -5
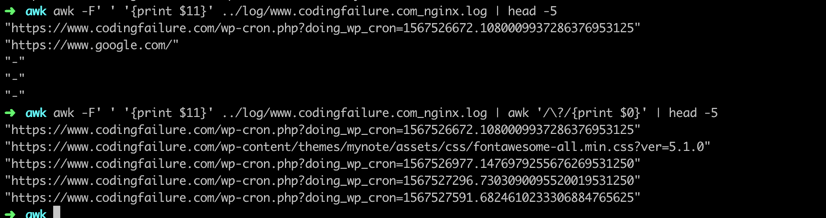
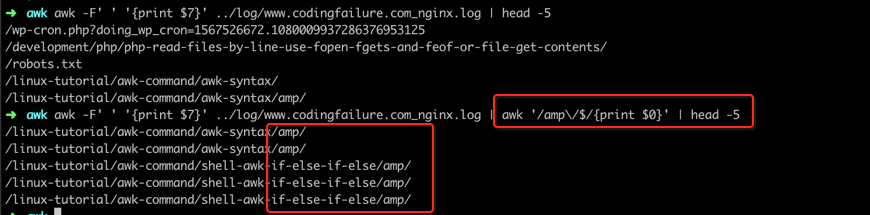
You need to escape these special characters using the backslash character (\).Awk using ERE regex Patterns
➜ awk -F' ' '{print $7}' ../log/www.linuxcommands.site_nginx.log | awk '/amp\/$/{print $0}' | head -5
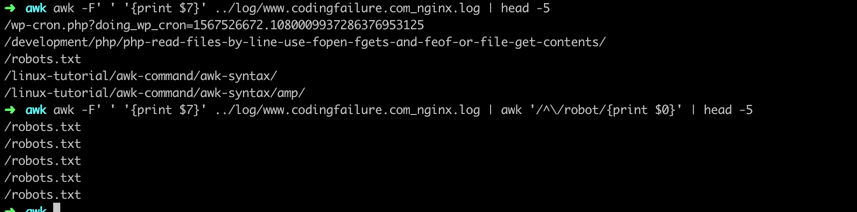
The caret character (^) matches the start of text:
➜ awk -F' ' '{print $7}' ../log/www.linuxcommands.site_nginx.log | awk '/^\/robot/{print $0}' | head -5
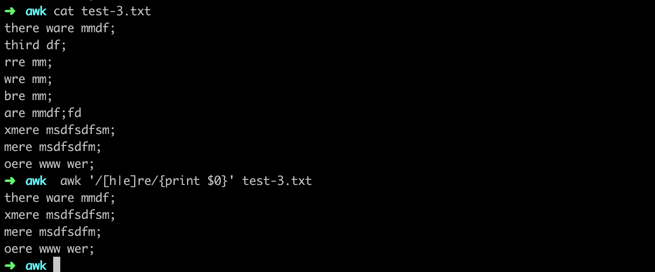
The character class is defined using square brackets [] like this:
➜ awk '/[h|e]re/{print $0}' test-3.txt
Ranges
➜ awk -F' ' '{print $7}' ../log/www.linuxcommands.site_nginx.log | awk '/[0-9]$/{print $0}' | head -5